

Preface
이 문서는 중국어 원서인 “입문 Visual SLAM 이론에서 연습까지 14 강(视觉SLAM十四讲 从理论到实践)” 책의 원저자로부터 한글 번역 허가를 받고 구글 번역기를 이용하여 작성된 문서입니다. 본 문서는 아래의 Contribution을 특징으로 합니다.
- 중국어 전공 서적을 구글 번역기를 이용해 한글로 초벌 번역했습니다.
- 초벌 번역 후 매끄럽지 않은 문장은 문맥에 맞게 수정되었습니다.
- 문서 내용 중 참고할만한 웹문서를 코멘트로 추가했습니다.
- SLAM 연구에서 주로 사용되는 용어는 한글로 번역된 용어보다 주로 사용되는 영어로 된 용어 그대로 표시하였습니다.
그럼에도 불구하고 부정확하거나 매끄럽지 않은 부분이 있을 수 있습니다. 그런 부분은 코멘트로 제안해주시면 반영하도록 노력하겠습니다. 또한 읽으시다가 잘 이해가 가지 않는 부분도 코멘트로 질문해주시면 답변해드리도록 하겠습니다.
번역 참가자:
신동원 (前 광주과학기술원 박사과정)
김선호 (前 VIRNECT 선임연구원)
조원재 (前 일본국립농업기술혁신공학센터 연구원)
장형기 (前 Imperial College London 석사과정)
박준영 (前 광주과학기술원 석사과정)
2018년 10월 1일
신동원 드림
제5장. 카메라 및 이미지
|
주요 목표
|
이전 두 강의에서는 로봇의 6 DoF 포즈를 표현하고 최적화하는 방법에 대한 문제를 소개하고 SLAM에서 변수의 의미와 운동 및 관찰 방정식을 부분적으로 설명했습니다. 이 장에서는 관찰 방정식의 일부인 "로봇이 외부 세계를 관찰하는 방법"에 대해 설명합니다. 카메라 기반 비주얼 SLAM에서 관찰은 주로 이미지 투영 프로세스를 나타냅니다.
우리는 실생활에서 많은 사진을 볼 수 있습니다. 컴퓨터에서 사진은 색상이나 밝기에 대한 정보를 기록하는 수백만 픽셀로 구성됩니다. 우리는 카메라의 광학 센터를 통과하고 카메라의 영상 평면에 투영된 3차원 세계에서 물체가 반사하거나 방출하는 빛을 볼 것입니다. 카메라의 광학 센서가 빛을 받으면 빛의 양을 측정하고 결과적으로 우리는 사진이라는 측정 결과를 얻습니다. 이 과정을 수학 방정식으로 어떻게 설명할 수 있을까요? 이 강의는 먼저 카메라 모델에 대해 논의하고 투영 관계가 어떻게 기술되는지 설명하고 이 투영 프로세스의 내부 매개 변수는 무엇인가를 설명합니다. 동시에, 우리는 또한 스테레오 및 RGB-D 카메라에 대한 간략한 소개를 제공할 것입니다. 그런 다음 OpenCV에서 2D 이미지의 기본 작동을 소개합니다. 마지막으로, 포인트 클라우드 정합의 실험은 내부 및 외부 매개 변수의 의미를 보여주기 위해 시연됩니다.
역자주: 이번 장에서는 컴퓨터 비전 및 영상 처리에서 가장 기본이 되는 3차원 공간을 수학적으로 나타내는 방법과 영상이 컴퓨터에서 표현되는 방법에 대해서 배웁니다. 핀홀, 양안, RGBD 카메라 모델, 컴퓨터에서 이미지의 표현 및 접근 등을 다루고 실습에서는 opencv와 pcl의 기본적인 내용에 대해 설명합니다. 다른 장 들에 비해서 쉬운 내용이니 가볍게 읽으실 수 있을 것 같습니다. 중심이 되는 키워드를 캐치하셔서 구글, 유튜브에서 검색하여 부가적인 자료를 통해 좀더 공부하시는 것도 도움이 될 것 같습니다 :-)
5.1 카메라 모델
3차원 세계의 좌표 점을 2 차원 이미지 평면 (픽셀 단위)에 매핑하는 프로세스는 기하학적 모델로 설명될 수 있습니다. 이 모델에는 많은 모델이 있으며, 그중 가장 간단한 모델은 핀홀 모델입니다. 핀홀 모델은 핀홀을 통한 빛의 투영과 핀홀의 후면 영상 간의 관계를 설명하는 매우 일반적이며 효과적인 모델입니다. 이 책에서는 간단한 핀홀 카메라 모델을 사용하여이 매핑을 모델링합니다. 동시에, 카메라에 렌즈가 존재하기 때문에 결상면에 광을 투사하는 과정에서 왜곡이 발생합니다. 따라서 우리는 핀홀과 왜곡의 두 가지 모델을 사용하여 전체 프로젝션 프로세스를 설명합니다.
이 섹션에서는 카메라의 핀홀 모델을 먼저 소개한 다음 렌즈의 왜곡 모델을 설명합니다. 이 두 모델은 카메라의 내부 영상 평면에 외부 3D 점을 투영하여 카메라의 내부 파라미터를 형성할 수 있습니다.
5.1.1 핀홀 카메라 모델
고등학교 물리 수업에서 우리는 양초 투영 실험을 해보았을 것입니다. 어두운 상자 앞에 불이 켜진 양초를 놓고, 양초의 빛은 작은 구멍을 통해 상자의 후면에 투사됩니다. 이 과정에서, 작은 구멍은 3차원 세계에서의 양초를 2차원 영상 평면으로 투영할 수 있습니다. 같은 이유로 우리는 그림 5-1과 같이 이 간단한 모델을 사용하여 카메라의 영상 프로세스를 설명할 수 있습니다.

이제 이 간단한 핀홀 모델을 기하학적으로 모델링해봅시다. O-x-y-z를 카메라 좌표계라고합시다. 카메라 앞 방향을 z 축으로 , 오른쪽으로 x축, 아래로 y축을 가리키는 것이 일반적입니다. O는 카메라의 광학 중심이며 핀홀 모델에서 핀홀이기도 합니다. 실세계의 공간 점 (P)는 작은 구멍 (O)을 통해 투사된 후에 물리적인 결상 평면 O'-x'-y '에 떨어지고, 해당 점은 P'라고 할 수 있습니다. P의 좌표를 $[X,Y,Z]^\mathrm{T}$라고하고 P'의 좌표를 $[X',Y',Z']^\mathrm{T}$라고할 때, 물리적 영상 평면에서 조리개까지의 거리를 f (초점 거리)로 설정할 수 있습니다. 그런 다음 삼각형의 닮음 법칙에 따라 다음을 알 수 있습니다.

음수 부호는 이미지가 반전되었음을 나타냅니다. 모델을 단순화하기 위해 그림 5-2의 중간 이미지와 같이 카메라 좌표계의 같은면에 있는 3D 공간 점과 함께 이미지면을 카메라의 전면에 대칭시킬 수 있습니다. 이렇게 하면 수식의 음수 기호가 제거되어 수식이보다 간결 해집니다.


X', Y'를 좌변에 넣으면

독자는 "영상 평면을 마음대로 앞쪽으로 움직여도 되나요?" 이렇게 물어볼 수도 있습니다. 이것은 실제 세계와 카메라 투영을 다루는 수학적 수단 일 뿐이며 카메라가 출력하는 대부분의 이미지는 뒤집어지지 않습니다. 카메라 자체의 소프트웨어가 이미지를 뒤집을 것이므로 일반적으로 위아래가 정렬된 이미지를 볼 수 있습니다. 이것은 대칭 영상 평면상의 이미지입니다. 그러므로 원래 영상은 물리적인 원리에 의해 거꾸로 된 이미지여야 하지만 이미지를 사전 처리했으므로 대칭 평면에서 이미지를 이해한다고 해서 작업에 해를 끼치 지 않습니다.
수식 (5.3)은 점 P와 그 이미지 사이의 공간적 관계를 기술합니다. 그러나 카메라에서는 영상 평면에서 샘플링 및 양자화해야하는 픽셀로 끝납니다. 센서가 감지된 빛을 이미지 픽셀로 변환하는 프로세스를 설명하기 위해 물리적 이미지 평면에 픽셀 평면 o-u-v를 설정합니다. 우리는 픽셀 평면에서 픽셀 좌표 $[u,v]^\mathrm{T}$를 얻습니다.
픽셀 좌표계는 일반적으로 원점 o'가 이미지의 왼쪽 위 모서리에 있고 u 축이 x 축에 평행하고 v 축이 y 축에 평행하도록 정의됩니다. 픽셀 좌표계와 이미지 평면 사이에는 원점의 줌과 이동 사이에 차이가 있습니다. 픽셀 좌표계와 이미지 평면 사이에는 원점의 줌과 이동 사이에 차이가 있습니다. 우리는 픽셀 좌표를 u축을 알파 값으로 크기 조정한 것과 v축을 베타 값으로 크기 조정한 것으로 설정합니다. 동시에 원점은 $[c_x, c_y]^\mathrm{T}$로 이동됩니다. 그러면, P '의 좌표와 픽셀 좌표 $[u,v]^\mathrm{T}$ 사이의 관계는 아래의 수식과 같습니다.

이때 이것을 수식 (5.3)에 $\alpha f$를 $f_x$로 대치하고, $\beta f$를 $f_y$로 대치하면 다음을 얻을 수 있습니다.

$f$는 미터법 단위이며, $\alpha, \beta$ 는 pixels/meter 단위이므로, $f_x, f_y$와 $c_x, c_y$는 픽셀 단위입니다. 이 형식을 행렬로 작성하는 것이 더 간결하지만 왼쪽에는 동차 좌표를, 오른쪽에는 동차 좌표가 아닌 좌표를 사용합니다.

전통적인 습관에 따라 Z를 왼쪽으로 옮겼습니다.

이 방정식에서는 중간 수량으로 구성된 행렬을 카메라의 내부 매개 변수 행렬 (Intrinsics) K라고 합니다.일반적으로 카메라의 내부 파라미터는 고정되며 사용 중에는 변경되지 않을 것으로 여겨집니다. 일부 카메라 제조업체는 카메라의 내부 매개 변수를 알려주고 때로는 직접 계산하여 카메라 파라미터를 결정해야 합니다.카메라 내부 매개 변수가 있으면 자연스럽게 외부 매개 변수가 있습니다. 식 (5.6)에서 우리는 카메라 좌표계에서 P의 좌표를 사용한다고 가정합니다. 카메라가 움직이기 때문에 P의 카메라 좌표는 카메라의 현재 자세를 기반으로 카메라 좌표계로 변환된 세계 좌표 $\mathbf{P}_w$여야 합니다. 카메라의 포즈는 회전 행렬 R과 변환 벡터 t로 설명됩니다. 그러면 다음과 같습니다.

후자의 공식은 homogeneous 좌표에서 non-homogeneous좌표로의 변환을 의미합니다. 이는 P의 세계 좌표와 픽셀 좌표의 투영 관계를 설명합니다. 그중에서도 카메라의 포즈 R, t는 카메라의 외부 매개 변수 (Camera extrinsics)라고도 합니다. 상수 내부 참조와 비교하여 카메라 이동에 따라 외부 참조가 변경되며 로봇의 궤적을 나타내는 SLAM으로 추정되는 대상이기도 합니다.
투영 절차는 다른 관점에서도 볼 수 있습니다. 식 (5.8)은 세계 좌표 점을 카메라 좌표계로 먼저 변환 한 다음 마지막 차원의 값 (카메라의 이미징 평면에서 점의 깊이)을 제거할 수 있음을 보여줍니다. 이는 마지막 차수를 반환하는 것과 같습니다. 일단 처리되면, 카메라의 정규화된 평면상의 점 P의 투영이 얻어진다 :
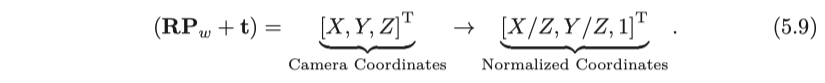
표준화된 좌표는 카메라 앞에 있는 z = 1에서 평면상의 점으로 볼 수 있습니다. 이 z = 1 평면은 정규화된 평면이라고도합니다. 정규화 된 좌표와 왼쪽 곱한 내부 매개 변수는 픽셀 좌표를 산출하므로 정규화 된 평면의 점을 양자화 한 결과로 픽셀 좌표$[u,v]^\mathrm{T}$를 생각할 수 있습니다. 이 모델에서 카메라 좌표에 0이 아닌 상수가 동시에 곱해지면 정규화 된 좌표가 같아서 투영 과정에서 점의 깊이가 손실되어 단안 시각이 사라진다는 것을 알 수 있습니다. 그래서 단안 비전에서는 단일 이미지에 의해 픽셀의 깊이 값을 얻을 수 없습니다.
5.1.2 왜곡
우리는 더 넓은 시야각의 이미지를 얻기 위해 카메라 앞에 렌즈를 추가할 수 있습니다. 렌즈의 추가는 영상을 생성하는 데 있어 빛의 전파에 새로운 영향을 줍니다. 하나는 렌즈 자체의 형상이 빛의 전파에 영향을 미치는 효과이고, 다른 하나는 기계적 조립 과정에서 렌즈와 이미지 평면이 완전히 평행할 수 없다는 것입니다. 빛이 렌즈를 통과할 때 영상 평면에서 상이 맺히는 위치가 바뀌는 것을 의미합니다.
렌즈 모양으로 인한 왜곡을 설명하는 몇 가지 수학적 모델이 있습니다. 핀홀 모델에서 직선은 픽셀 평면에 투영될 때 직선을 유지합니다. 그러나 실제로 찍은 사진에서 카메라의 렌즈는 실제 환경에서의 직선을 촬영된 영상에서 곡선으로 만드는 경향이 있습니다. 왜곡은 이미지의 가장자리로 갈수록 현상이 더욱 확연히 드러납니다. 실제로 생성된 렌즈는 종종 중심 대칭이기 때문에 일반적으로 불규칙한 왜곡이 일반적으로 반경 방향으로 대칭됩니다. 이들은 그림 5-3에서 볼 수 있듯이 배럴 왜곡과 핀쿠션 왜곡의 두 가지 주요 범주로 나뉩니다.
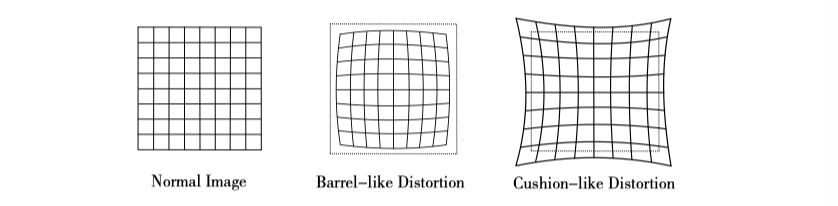
배럴 왜곡은 광축으로부터의 거리가 증가함에 따라 픽셀의 반경이 감소한다는 사실에 기인합니다. 핀쿠션 왜곡은 정반대입니다. 이 두 종류의 왜곡에서 이미지 중심과 광학 축의 교차점을 지나는 선은 여전히 모양을 유지할 수 있습니다.
렌즈의 모양 외에도 방사상의 왜곡이 발생할 수 있습니다. 카메라의 조립 과정에서 렌즈와 이미지 표면은 정확히 평행할 수 없으므로 접선 왜곡이 발생할 수 있습니다 (그림 5-4 참조).

방사형 및 접선 왜곡을 보다 잘 이해하기 위해 두 가지를 더 엄격한 수학적 형식으로 설명합니다. 정규화된 평면에 위치해 있는 어떤 점 $\mathbf{p}$를 생각해봅시다. 이 점은 $[x,y]^\mathrm{T}$로 나타내거나 또는 극좌표계 $[r, \theta]^\mathrm{T}$로 나타낼 수 있습니다 (r은 점 p와 좌표계 중심 사이의 거리를 나타내고 $\theta$는 수평축과의 각도를 나타냄). 방사형 왜곡은 길이를 따라 좌표 점의 변화, 즉 원점으로부터의 반경으로 볼 수 있습니다. 접선 왜곡은 접선 방향을 따라 좌표 점의 변화, 즉 수평각이 변경된 것으로 볼 수 있습니다. 일반적으로 이러한 왜곡은 다항식이라고 가정합니다.

여기서 $[x, y]$는 정규화된 평면 점의 좌표이며, $[x_\mathrm{distorted}, y_\mathrm{distorted}]^\mathrm{T}$ 는 왜곡 후의 점의 좌표입니다. 한편 접선 왜곡의 경우 다른 두 매개 변수 인 $p_1,p_2$를 사용하여 보정할 수 있습니다.

수식 (5.10)과 (5.11)을 합치면 5 개의 왜곡 계수가 있는 결합 모델이 생성됩니다. 완전한 양식은 다음과 같습니다.

위의 왜곡을 보정하는 과정에서 5 가지 왜곡 항을 사용했습니다. 실제 응용 프로그램에서는 $k_1, p_1, p_2$ 또는 $k_1, k_2, p_1, p_2$ 만 선택하는 등 유연하게 모델 수정을 선택할 수 있습니다.
이 섹션에서는 핀홀 모델을 사용하여 카메라의 이미징 프로세스를 모델링하고 렌즈 유도 방사형 및 접선 왜곡을 모델링했습니다. 실제 이미지 시스템에서 학자들은 아핀 모델 및 카메라의 원근감 모델과 같은 많은 다른 모델을 제안했으며 다른 많은 유형의 왜곡이 있습니다. 일반적인 SLAM에서 일반 카메라가 일반적으로 사용되는 것을 고려하면 핀홀 모델과 방사형 왜곡 및 접선 왜곡 모델로 충분하기 때문에 다른 모델에 대해서는 설명하지 않습니다.
왜곡 제거 (또는 수정)에는 두 가지 방법이 있습니다. 먼저 전체 이미지를 왜곡하지 않고 수정된 이미지를 얻은 다음 이미지에 있는 점의 공간적 위치를 논의할 수 있습니다. 또는 왜곡된 이미지의 일부 특징점을 논의하고 왜곡 방정식을 통해 실제 위치를 찾을 수도 있습니다. 둘 다 가능하지만 전자는 시각적 SLAM에서 더 일반적으로 보입니다. 따라서 이미지가 왜곡되지 않은 경우 왜곡을 고려하지 않고 핀홀 모델과 직접 투영 관계를 설정할 수 있습니다. 따라서 다음 논의에서 이미지가 왜곡되지 않았다고 직접 가정할 수 있습니다.
마지막으로 단안 카메라의 이미징 프로세스를 요약해 보겠습니다.
- 먼저, 월드 좌표계에 고정 점 $P$가 있고 그 점의 월드 좌표는 $\mathbf{P}_w$입니다.
- 카메라가 움직이기 때문에, 그것의 움직임은 $\mathbf{R}, \mathbf{t}$ 또는 변환 행렬 T ($\mathbf{T} \in \mathrm{SE}(3)$)로 기술된다. P의 카메라 좌표는 $\mathbf{\tilde{P}}_c = \mathbf{R} \mathbf{P}_w + \mathbf{t}$입니다.
- $\mathbf{\tilde{P}}_c$는 $X,Y,Z$이고 정규화된 평면 Z=1 투영되어 정규화된 좌표계로 표현할 수 있습니다.
- 이미지에 왜곡이 있을 때, 왜곡 후의 $\mathbf{P}_c$의 좌표는 왜곡 파라미터에 따라 계산된다. (왜곡 보정)
- 마지막으로, P의 정규화 된 좌표는 내부 파라미터를 통과하고 픽셀 좌표 $\mathbf{P}_{uv} = \mathbf{K} \mathbf{P}_c$에 해당합니다. (내부 파라미터)
요약하면 우리는 세계 좌표, 카메라 좌표, 정규화된 좌표 및 픽셀 좌표의 네 가지 좌표에 대해 이야기했습니다. 독자는 전체 이미징 프로세스를 반영하고 미래에 사용될 관계를 명확히 해야 합니다.
5.1.3 양안 카메라 모델
핀홀 카메라 모델은 단일 카메라의 이미징 모델을 설명합니다. 그러나 단일 픽셀만을 이용하여 공간 지점의 특정 위치를 결정할 수는 없습니다. 이는 카메라의 광학 중심에서 정규화된 평면까지의 선의 모든 점이 해당 픽셀에 투사될 수 있기 때문입니다. P의 깊이가 결정된 경우에만 (양안 또는 RGB-D 카메라를 통해) 그림 5-5와 같이 공간 위치를 정확하게 알 수 있습니다.
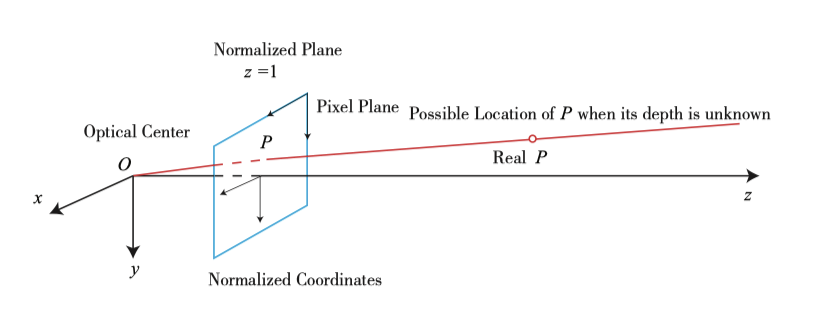
픽셀 거리 (또는 깊이)를 측정하는 방법은 여러 가지가 있습니다. 예를 들어, 인간의 눈은 왼쪽 눈과 오른쪽 눈이 보는 장면 차이 (또는 시차)에 따라 물체와 우리 사이의 거리를 판단할 수 있습니다. 양안 카메라의 원리도 동일합니다 : 왼쪽과 오른쪽 카메라의 이미지를 동시에 얻고 이미지 간의 시차를 계산하여 각 픽셀의 깊이를 추정합니다. 다음은 양안 카메라의 영상 원리를 간략히 설명합니다 (그림 5-6 참조).
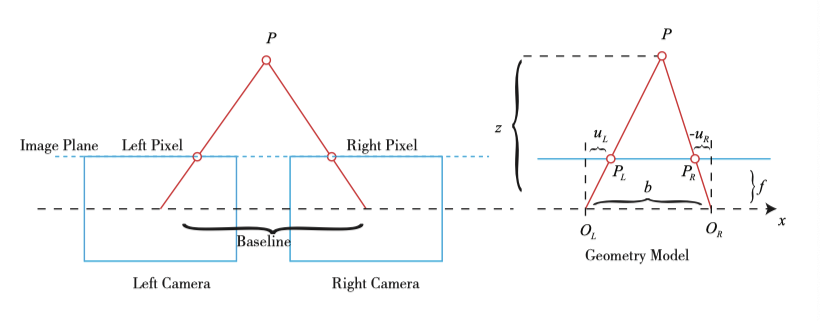
양안 카메라는 일반적으로 두 개의 수평으로 배치된 카메라인 왼쪽 카메라와 오른쪽 카메라로 구성됩니다. 왼쪽과 오른쪽 양안 카메라에서는 두 카메라를 모두 핀홀 카메라로 취급할 수 있습니다. 두 카메라의 조리개 중심이 x 축에 있음을 의미하는 수평 배치입니다. 이 둘 사이의 거리를 양안 카메라의 베이스 라인이라고 부릅니다 (베이스 라인, b로 표시). 양안 카메라의 중요한 매개 변수입니다.
3차원 점 P가 각 영상에 사영되었을 때 영상 평면에서의 점 좌표를 $P_L, P_R$라고 합시다. 두 점의 위치는 카메라 베이스라인의 존재로 인해 다릅니다. 이상적으로, 왼쪽 및 오른쪽 카메라는 x축상에서의 차이만을 가지기 때문에 P의 이미지는 x 축에 대해서만 차이가 발생합니다. 그런 다음 그 기하학적 관계가 그림 (5-6)의 오른쪽에 표시됩니다. $ \triangle P P_L P_R$ 와 $\triangle P O_L O_R$ 간의 삼각형 닮음 관계에 따르면,

약간의 정리를 하면:

여기서, d는 좌우 수치의 가로 좌표 사이의 차이이며, 디스패러티 (Disparity)라고 불린다. 시차를 기반으로 픽셀과 카메라 사이의 거리를 추정할 수 있습니다. 시차는 거리에 반비례합니다. 시차가 클수록 거리가 가까워집니다. 동시에 시차는 적어도 하나의 픽셀이기 때문에 fb에 의해 결정되는 양안 깊이에 대한 이론상의 최대 값이 있습니다. 베이스 라인이 길어질수록 양안이 측정할 수있는 최대 거리가 멀어지고 반대로 작은 베이스 라인은 아주 가까운 거리 만 측정 할 수 있습니다.
시차로부터 깊이를 계산하는 공식은 매우 간단하지만, 시차 d 자체의 계산은 어렵다. 우리는 우안 영상에 좌안 영상의 픽셀이 나타나는 위치를 정확히 알아야 합니다. 즉, 이는 "사람이 쉽게 찾을 수 있고 컴퓨터가 어렵다고 판단하는"작업이기도 합니다. 이미지의 각 픽셀의 깊이를 계산하고 싶을 때 계산량과 정확도가 문제가 되고, 이미지 질감이 풍부한 곳에서만 시차를 계산할 수 있습니다. 계산의 양으로 인해 양안 깊이 추정은 거리 계산을 실시간으로 실행하기 위해 GPU 또는 FPGA를 사용해야 합니다. 이것은 강의 13에서 언급될 것입니다.
5.1.4 RGB-D 카메라 모델
양안 카메라가 시차로 깊이를 계산하는 것보다 RGB-D 카메라로 깊이를 측정하는 것이 더 직접적이며 각 픽셀의 깊이를 능동적으로 측정할 수 있습니다. 현재 RGB-D 카메라는 원칙에 따라 두 가지 범주로 나눌 수 있습니다 (그림 5-7 참조).
- 픽셀 거리는 Structured Light에 의해 측정됩니다. Kinect v1, Project Tango 1 세대, Intel RealSense 등이 그 예입니다.
- 픽셀 거리는 비행시간 방법 (Time-of-flight)에 의해 측정됩니다. 예는 Kinect v2 세대 및 일부 기존 ToF 센서입니다.

유형에 관계없이 RGB-D 카메라는 대상에 빛의 광선 (일반적으로 적외선)을 방출해야 합니다. 구조화된 빛(structured light) 원리에서 카메라는 반환된 구조화된 조명 패턴을 기반으로 객체와 객체 사이의 거리를 계산합니다. ToF 원리에서 카메라는 빛을 물체에 방출 한 다음 반사되어 돌아왔을 때의 빛의 비행시간을 기준으로 대상과 물체 사이의 거리를 결정합니다. ToF 원리는 레이저 센서와 매우 유사합니다. 단 레이저는 점진적인 스캐닝으로 거리를 얻는 반면 ToF 카메라는 RGB-D 카메라의 특성인 전체 이미지의 픽셀 깊이를 얻을 수 있습니다. 따라서 RGB-D 카메라를 분해해보면 일반적으로 일반 카메라 외에 적어도 하나의 송신기와 수신기가 있습니다.
깊이를 측정한 후, RGB-D 카메라는 일반적으로 각 카메라의 위치에 따라 깊이와 컬러 맵 픽셀 간의 쌍을 완성하고 일대일 대응 컬러 맵과 깊이 맵을 출력 합니다. 동일한 이미지 위치에서 색상 정보와 거리 정보를 읽고 픽셀의 3D 카메라 좌표를 계산하고 점군을 생성할 수 있습니다. RGB-D 데이터의 경우 이미지 레벨 또는 포인트 클라우드 레벨에서 처리할 수 있습니다. 이 강의의 두 번째 실험에서는 RGB-D 카메라의 포인트 클라우드 구축 과정을 보여줍니다.
RGB-D 카메라는 각 픽셀의 거리를 실시간으로 측정합니다. 그러나, 이러한 유형의 송수신 측정으로 인해, 그 사용 범위는 제한적이다. 깊이 측정을 위해 적외선을 사용하는 RGB-D 카메라는 네온 또는 기타 센서에서 방출되는 적외선으로부터 간섭받기 쉽기 때문에 실외에서 사용할 수 없으며 여러 번 사용하면 서로 간섭을 일으킬 수 있습니다. 투과성 물질을 가진 물체의 경우, 반사광을 받지 않기 때문에 이 점들의 위치를 측정할 수 없습니다. 또한 RGB-D 카메라는 비용 및 전력 소비면에서 몇 가지 단점이 있습니다.
5.2 이미지
카메라와 렌즈는 3차원 세계의 정보를 픽셀 사진으로 변환 한 다음 후속 처리를 위해 데이터 소스로 컴퓨터에 저장합니다. 수학에서 이미지는 행렬로 기술할 수 있으며 컴퓨터에서는 2차원 배열로 표현할 수 있는 연속 디스크 또는 메모리 공간을 차지합니다. 이 방법으로 프로그램은 숫자 행렬 또는 의미 있는 이미지를 처리하는지 여부를 구별할 필요가 없습니다.
이 섹션에서는 컴퓨터 이미지 프로세싱의 기본 작업을 소개합니다. 특히 OpenCV의 이미지 데이터 처리를 통해 컴퓨터에서 이미지를 처리하는 일반적인 단계는 이후 장의 기초를 마련하는 것입니다. 가장 간단한 이미지, 그레이 스케일 이미지부터 시작해 보겠습니다. 그레이 스케일 이미지에서 각 픽셀 위치 (x, y)는 그레이 스케일 이미지에서의 intensity에 해당하므로 너비가 w이고 높이가 h 인 이미지를 수학적으로 행렬로 다음과 같이 기록할 수 있습니다.

그러나 컴퓨터는 전체 실제 공간을 표현하지 않으므로 특정 범위 내의 이미지만 양자화할 수 있습니다. 예를 들어, 일반적인 그레이 스케일 이미지에서, 0 내지 255의 정수 (즉, 부호 없는 문자, 1 바이트)가 이미지의 그레이 스케일을 표현하는 데 사용됩니다. 그다음, 640 픽셀의 폭 및 480 픽셀의 해상도를 갖는 그레이 스케일 이미지는 다음과 같이 표현될 수 있습니다.

왜 2D 배열이 480X640일까요? 프로그램에서 이미지는 2차원 배열로 저장되기 때문에. 첫 번째 첨자는 행을 나타내고 두 번째 첨자는 열을 나타냅니다. 이미지에서 배열의 행 수는 이미지 높이에 해당하며 열 수는 이미지 너비에 해당합니다.
이 이미지의 내용을 살펴보겠습니다. 이미지는 자연스럽게 픽셀로 구성됩니다. 픽셀에 접근할 때 그림 (5-8)에서와 같이 픽셀이 있는 좌표를 나타내야 합니다.
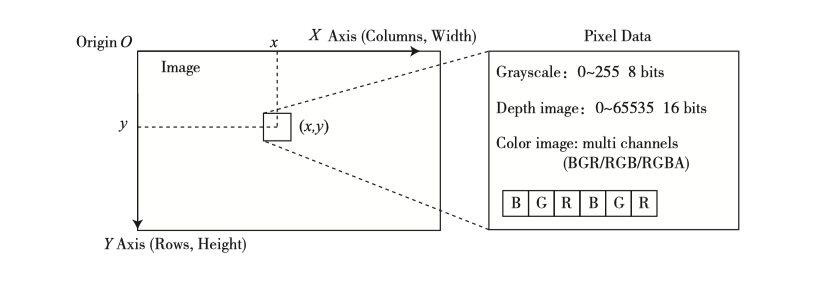
그림 5-8의 왼쪽에는 전통적인 픽셀 좌표계가 정의되어 있습니다. 픽셀 좌표계의 원점은 이미지의 왼쪽 위 모서리에 있으며 X 축은 오른쪽을 향하고 Y 축은 아래쪽을 향합니다. 세 번째 축인 Z 축이 있으며 오른손 법칙에 따라 Z 축은 정면 방향을 향합니다. 이 정의는 카메라 좌표계와 일치합니다. 우리가 일반적으로 말하는 열의 폭 또는 수는 X 축에 해당하며 이미지의 행 또는 높이의 수는 Y 축에 해당합니다.
이 정의에 따르면 x, y에서 픽셀을 논의하면 프로그램에서의 액세스는 다음과 같아야 합니다.

이것은 그레이 스케일 값 I(x, y)에 대응합니다. 여기서 x와 y의 순서를 주의하십시오. 우리가 좌표계의 문제를 논의하는 것을 귀찮게 하지는 않지만이 첨자 순서와 같은 오류는 초보자가 디버깅하는 동안 자주 접하게 되는 오류 중 하나이며 숨겨진 오류가 있습니다. 프로그램을 작성할 때 우연히 x, y 좌표를 변경하면 컴파일러는 정보를 제공할 수 없으며 프로그램 실행 중에 범위를 벗어난 오류가 표시됩니다.
픽셀의 그레이 레벨은 0에서 255 사이의 값입니다. 8 비트 정수가 기록됩니다. 더 많은 정보를 얻으려면 1 바이트가 필요합니다. 예를 들어, RGB-D 카메라의 깊이 맵에서 이 값은 일반적으로 밀리미터이며, RGB-D 카메라의 범위는 일반적으로 약 12 미터인데 이 것은 255 이상입니다. 이때 사람들은 깊이 맵 정보, 즉 0에서 65536 사이의 값을 기록하기 위해 16 비트 정수 (부호 없는 C ++의 약자)를 사용합니다. 미터법으로 변환하면 RGB-D 카메라의 경우 최대 65 미터까지 표시할 수 있습니다.
컬러 이미지의 표현에는 채널의 개념이 필요합니다. 컴퓨터에서 우리는 빨강, 초록, 파랑의 3가지 색상 조합을 사용하여 색상을 표현합니다. 따라서, 각 화소마다 R, G, B의 3개의 값이 기록되고, 각 값을 채널이라고 부릅니다. 예를 들어, 가장 보편적인 컬러 이미지는 3개의 채널을 가지며, 각각은 8 비트 정수로 표현됩니다. 이 규칙에 따라 하나의 픽셀은 24 비트의 공간을 차지합니다.
채널 수와 순서는 자유롭게 정의할 수 있습니다. OpenCV 컬러 이미지에서 채널의 기본 순서는 B, G, R입니다. 즉, 24 비트 픽셀을 얻으면 처음 8 비트는 파란색 값을 나타내고 중간 8 비트는 녹색이며 마지막 8 비트는 빨간색입니다. 유사하게, 컬러 맵은 R, G 및 B의 순서로 표현될 수 있다. 이미지의 투명도를 표현하려면 R, G, B 및 A의 네 가지 채널을 사용할 수 있습니다.
5.3 실습 : 이미지 접근 및 처리
5.3.1 OpenCV의 기본적인 사용방법
데모 프로그램을 사용하여 OpenCV에서 이미지에 액세스하는 방법과 그 안에있는 픽셀에 액세스하는 방법을 이해합시다.
OpenCV 설치
OpenCV는 많은 오픈 소스 이미지 알고리즘을 제공합니다. 컴퓨터 비전에서 널리 사용되는 이미지 처리 알고리즘 라이브러리입니다. 이 책은 기본 이미지 처리를 위해 OpenCV도 사용합니다. 이를 사용하기 전에 독자가 소스 코드에서 설치하는 것이 좋습니다. Ubuntu에서는 소스 코드에서 설치하고 라이브러리 파일만 설치하는 두 가지 방법이 있습니다.
- 소스 코드에서 설치한다는 것은 OpenCV 웹 사이트에서 모든 OpenCV 소스 코드를 다운로드하고 사용하기 위해 컴파일하고 설치하는 것을 의미합니다. 장점은 선택할 수 있는 버전이 풍부하고 소스 코드를 볼 수 있지만 컴파일 시간이 소요된다는 것입니다.
- 라이브러리 파일만 설치한다는 것은 Ubuntu 커뮤니티 직원이 Ubuntu를 통해 컴파일 한 라이브러리 파일을 설치한다는 의미이므로 다시 컴파일하지 않아도 됩니다.
최신 버전의 OpenCV를 사용하려고 하므로 소스 코드에서 설치해야 합니다. 결과적으로 프로그래밍 환경에 맞게 일부 컴파일 옵션을 조정할 수 있습니다 (예 : GPU 가속이 필요 없음). 또한 소스 코드를 설치하면 몇 가지 추가 기능을 사용할 수 있습니다. OpenCV는 현재 OpenCV 2.4 시리즈와 OpenCV 3 시리즈로 구분되는 두 가지 주요 버전을 유지합니다. 이 책은 OpenCV 3 시리즈를 사용합니다.
독자는 http://opencv.org/downloads.html에서 다운로드하여 Linux 용 OpenCV 버전을 선택할 수 있습니다. opencv-3.1.0.zip과 같은 압축 파일을 받게 됩니다. 그것을 임의의 디렉터리에 추출하면 OpenCV도 cmake 프로젝트라는 것을 알 수 있습니다.
컴파일하기 전에 OpenCV 종속성을 설치하십시오.

실제로는 OpenCV는 많은 의존성을 가지고 있으며 일부 누락된 컴파일러는 일부 기능에 영향을 미칩니다 (그러나 모든 기능을 사용하지는 않습니다). OpenCV는 cmake 단계에서 종속성이 설치되고 기능을 조정하는지 확인합니다. 컴퓨터에 GPU가 있고 관련 종속성이 설치된 경우 OpenCV는 GPU의 속도를 높입니다. 그러나 이 책에서 위의 의존성은 충분합니다.
이후의 컴파일과 설치는 일반 cmake 프로젝트와 동일합니다. make가 끝나면 "sudo make install"을 호출하여 OpenCV를 컴퓨터에 설치합니다 (컴파일하는 대신). 컴퓨터 구성에 따라 이 컴파일 프로세스는 20분에서 1시간 정도 걸릴 수 있습니다. 멀티코어의 CPU를 사용하는 경우 "make -j4"와 같은 명령을 사용하여 여러 스레드를 호출하여 컴파일할 수 있습니다 (-j 이후의 인수는 CPU 코어의 수를 적으면 됩니다). 설치 후 OpenCV는 기본적으로 /usr/local 디렉터리에 저장됩니다. OpenCV 헤더 파일과 라이브러리 파일이 설치되어있는 위치를 찾을 수 있습니다. 또한 이전에 0penCV 2 시리즈를 설치한 경우 OpenCV 3을 다른 위치에 설치하는 것이 좋습니다 (이것이 어떻게 작동하는지 생각하십시오).
5.3.2 OpenCV 이미지 조작
이제 간단한 예제에서 OpenCV에서 기본 이미지 작업을 수행해 봅시다.
소스코드: slambook/ch5/imageBasics/imageBasic.cpp
이 예에서는 이미지 읽기, 표시, 픽셀 순회, 복사, 할당 등의 작업을 보여줍니다. 대부분의 주석은 코드로 작성되었습니다. 프로그램을 컴파일할 때 CMakeLists.txt에 OpenCV 헤더 파일을 추가 한 다음 프로그램을 라이브러리 파일에 연결해야 합니다. 또한 C ++ 11 표준 (nullptr 및 chrono와 같은)을 사용하고 있으므로 컴파일러를 설정해야 합니다.
소스코드: slambook/ch5/imageBasics/CMakkeLists.txt

코드와 관련하여 몇 가지 메모를 제공합니다.
- 프로그램은 명령 행의 첫 번째 매개 변수 인 argv [1]에서 이미지 위치를 읽습니다. 우리는 독자를 위한 이미지 (ubuntu.png)를 테스트 용으로 준비했습니다. 따라서 컴파일한 후 다음 명령을 사용하여 이 프로그램을 호출할 수 있습니다.

IDE에서 이 프로그램을 호출하는 경우 동시에 매개 변수를 제공해야 합니다. Clion을 사용하는 경우 시작 구성 대화 상자에서 구성할 수 있습니다. - 프로그램의 10 ~ 18 행은 cv::imread 함수를 사용하여 이미지를 읽고 이미지와 기본 정보를 표시합니다.
- 35 ~ 46 행에서는 이미지의 모든 픽셀을 순회하며 전체 루프에 소요된 시간을 계산합니다. 픽셀이 통과하는 방식은 고유하지 않으며 루틴이 제공되는 방식이 가장 효율적이지 않습니다. OpenCV는 반복자를 통해 이미지의 픽셀을 탐색할 수 있는 반복 기를 제공합니다. 또는 cv::Mat::data는 이미지 데이터의 시작 부분에 대한 포인터를 제공합니다. 포인터에서 직접 오프셋을 계산 한 다음 픽셀의 실제 메모리 위치를 얻을 수 있습니다. 루틴이 사용되는 방식은 독자가 이미지의 구조를 이해하도록 하는 것입니다. 작성자의 컴퓨터 (가상 컴퓨터)에서 이 이미지를 가로지르는 데 약 12.74ms가 걸립니다. 자신의 컴퓨터에서 속도를 비교할 수 있습니다. 그러나 우리는 cmake의 기본 디버그 모드를 사용하고 있습니다. 릴리스 모드를 사용하면 훨씬 빠릅니다.
- OpenCV는 이미지 조작을 위한 여러 가지 기능을 제공합니다. 여기서는 나열하지 않겠습니다. 그렇지 않으면 책이 OpenCV 개발자 문서처럼 복잡해집니다. 이 예제는 이미지 읽기 및 표시와 같은 가장 일반적인 사항과 cv::Mat의 깊은 복사 기능을 보여줍니다. 프로그래밍 과정에서 독자는 이미지 회전 및 보간과 같은 작업도 경험하게 됩니다. 이때 기능의 원리와 사용법을 이해하려면 해당 기능 문서를 참조해야 합니다.
OpenCV가 유일한 이미지 라이브러리가 아니라 많은 이미지 라이브러리에서 널리 사용되는 것 중 하나임을 주목해야 합니다. 그러나 대부분의 이미지 라이브러리는 이미지와 비슷한 표현식을 사용합니다. 독자가 OpenCV의 이미지 표현을 이해하고 다른 라이브러리의 이미지 표현을 이해하여 데이터 형식이 필요할 때 직접 처리할 수 있기를 바랍니다.
또한 cv::Mat는 매트릭스 클래스이기 때문에 이미지를 표현하는 것 외에도 포즈와 같은 매트릭스 데이터를 저장할 수 있습니다. 일반적으로 Eigen은 고정 크기 행렬에 더 효율적이라고 여겨집니다.
5.3.3 이미지 왜곡 보정
이전 섹션에서 rad-tan distortion 모델을 도입했습니다. 이제 구현을 보여주는 예를 작성해봅시다. OpenCV는 우리를 위한 cv::Undistorted 함수를 제공하지만 기본 개념을 소개하기 위해 손으로 작성된 undistortion 함수 기능을 제공할 것입니다.
소스코드: slambook/ch5/imageBasics/undistortImage.cpp
두 이미지의 차이점을 직접 확인하십시오.
5.4 연습: 3D Vision
5.4.1 스테레오 비전
우리는 스테레오 비전의 이미징 원리를 도입했습니다. 이제 왼쪽 및 오른쪽 이미지에서 시작하고 왼쪽 눈에 해당하는 디스 패리티 맵을 계산 한 다음 카메라 좌표계에서 각 픽셀의 좌표를 계산하여 포인트 클라우드를 형성합니다. 우리는 그림 5-9와 같이 독자가 왼쪽 및 오른쪽 이미지를 준비했습니다. 다음 코드는 디스패리티 맵 및 포인트 클라우드의 계산을 보여줍니다.
소스코드: slambook/ch5/stereoVision/stereoVision.cpp
이 예에서는 왼쪽 및 오른쪽 이미지의 디스 패리티를 계산하기 위해 OpenCV에서 구현된 SGBM (Semi Global Batch Matching) [26] 알고리즘을 호출 한 다음 양안 카메라의 기하학적 모델을 통해 카메라의 3D 공간으로 변환합니다. 우리는 인터넷에서 고전적인 매개 변수 구성을 사용하며 주로 최대 및 최소 불균형을 조정합니다. 카메라의 내부 매개 변수와 기준선과 결합된 불일치 데이터는 3차원 공간에서 각 점의 위치를 결정할 수 있습니다. 일부 공간을 저장하기 위해 포인트 클라우드를 표시하는 것과 관련된 코드를 생략합니다.
이 책은 양안 카메라의 시차 계산 알고리즘을 소개하지 않을 것입니다. 관심 있는 독자는 관련 참고 문헌을 읽을 수 있습니다 [27, 28]. OpenCV에서 구현 한 쌍안 알고리즘 외에도 효율적인 시차 계산을 달성하는 데 초점을 맞춘 다른 많은 라이브러리가 있습니다. 오늘날에도 여전히 활발하고 복잡한 주제입니다.
5.4.2 RGB-D Vision
마지막으로 카메라의 내부 및 외부 매개 변수를 사용하는 방법을 연습해 봅니다. 이 섹션에서는 5 개의 RGB-D 이미지를 제공하며 각 이미지의 내부 및 외부 매개 변수를 알고 있다고 가정합니다. RGB-D 이미지와 카메라 내부 파라미터를 기반으로 카메라 좌표계에서 모든 픽셀의 위치를 계산할 수 있습니다. 동시에, 카메라 자세에 따라, 월드 좌표계에서 이들 픽셀의 위치를 계산할 수 있습니다. 모든 픽셀의 공간 좌표를 찾으면 맵과 비슷한 것을 구성하는 것과 같습니다. 이제 연습 해 봅시다.
우리는 slambook2/ch5/rgbd 폴더에 있는 5 쌍의 이미지를 준비했습니다. color 폴더에 1.png에서 5.png까지 5 개의 RGB 이미지가 있고 depth 폴더에 5 개의 해당 깊이 맵이 있습니다. 동시에 pose.txt 파일은 카메라 포즈 ($ \mathbf{T}_\mathrm{wc} $)로 5 개의 이미지를 제공합니다. 카메라 포즈의 형식은 이동 벡터 + 회전 쿼터니언입니다.

여기서 q_w는 쿼터니언의 실수 부분입니다. 예를 들어, 그래프의 첫 번째 쌍의 외부 매개 변수는 다음과 같습니다.
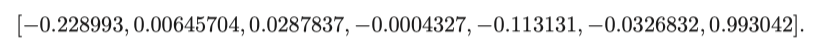
아래의 두 가지를 완료하는 프로그램을 작성합니다. (1) 내부 매개 변수에 따라 RGB-D 이미지 쌍에 해당하는 포인트 클라우드를 계산합니다. (2) 각 그림의 카메라 포즈 (즉, 외부 매개 변수)에 따라, 점 구름이 합쳐지도를 형성합니다.
소스코드: slambook/ch5/rgbdd/joinMap.cpp

Pangolin을 활용하여 뷰어를 만든 후 포인트 클라우드를 볼 수 있습니다 (그림 5-10 참조).
이 예제를 통해 우리는 컴퓨터 비전에서 일반적인 단안, 쌍안 및 깊이 카메라 알고리즘을 시연했습니다. 독자들이 이 간단한 예제를 통해 내부, 외부, 왜곡 모델의 의미를 이해할 수 있기를 바랍니다.
'입문 SLAM 14강 (번역)' 카테고리의 다른 글
| 입문 Visual SLAM 14강 : 4장. Lie군과 Lie 대수 (0) | 2021.03.25 |
|---|---|
| 입문 Visual SLAM 14강 : 3장. 3차원 공간 강체 변환 (0) | 2021.03.08 |
| 입문 Visual SLAM 14강 : 참고문헌 (0) | 2021.02.17 |
| 입문 Visual SLAM 14강 : 2장. SLAM과의 첫만남 (0) | 2021.02.17 |
| 입문 Visual SLAM 14강 : 1장. 선행지식 (0) | 2021.02.17 |



